[OS] 개발 편의성을 위한 Windows 환경 세팅하기 - chocolately


물론 개발을 위한 환경으로 Linux 환경이라면 정말 편하겠지만,,,
업무 편의성을 위해 Windows OS가 설치되어있는 PC에 환경 세팅이 필요한 경우가 있다.
혹은 개발용 PC가 아니지만, 간단한 데이터 작업 혹은 IT Tech 관련 업무가 필요할 때 !!
1.Windows용 패키지 관리자 Chocolatey(choco) 란?

- Chocolately 는 Windows의 패키지 매니저 : 필요한 설치 프로그램(Pakage)를 설치/업데이트/제거 등 관리
- Likes, Linux의 yum/apt(-get) 또는 Mac의 Homevrew
- 공식 설치 홈페이지 : https://chocolatey.org/
Chocolatey - The package manager for Windows
Chocolatey is software management automation for Windows that wraps installers, executables, zips, and scripts into compiled packages. Chocolatey integrates w/SCCM, Puppet, Chef, etc. Chocolatey is trusted by businesses to manage software deployments.
chocolatey.org
2. 설치 방법
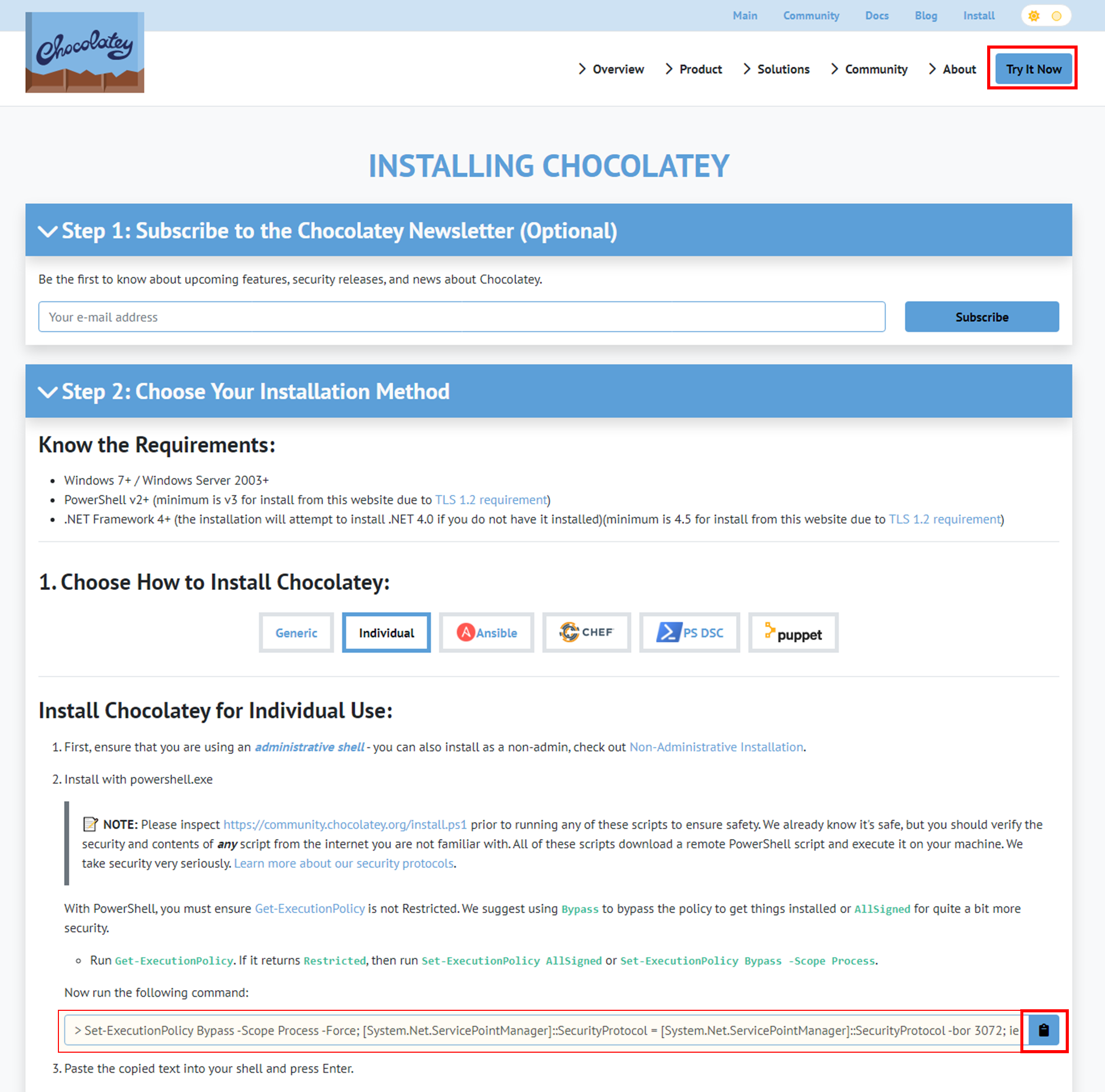
1) Copy Command for Downloading
- 홈페이지 > 우측 상단의 Try It Now > Step 2의 Now run the following command 하단의 명령어 복사(클립보드 아이콘)
2) Running on PowerShell
- 윈도우 검색 혹은 탐색기에서 Shift+마우스 우클릭 > PowerShell - 관리자(권한으)로 실행 > 복사한 명령어 실행
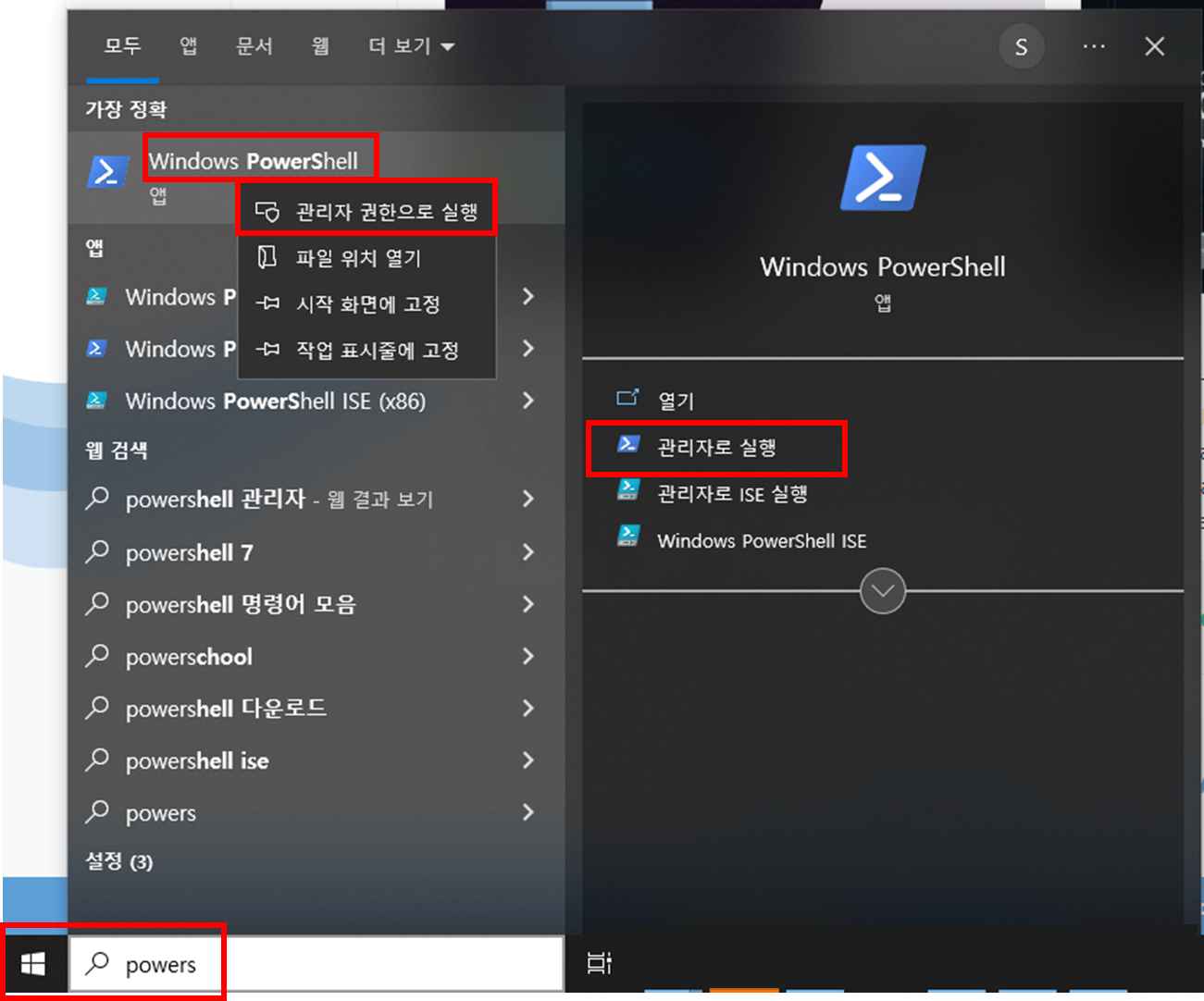
- 복사한 명령어 그대로 붙여넣고, 엔터!!!!! > PowerShell 창 닫기
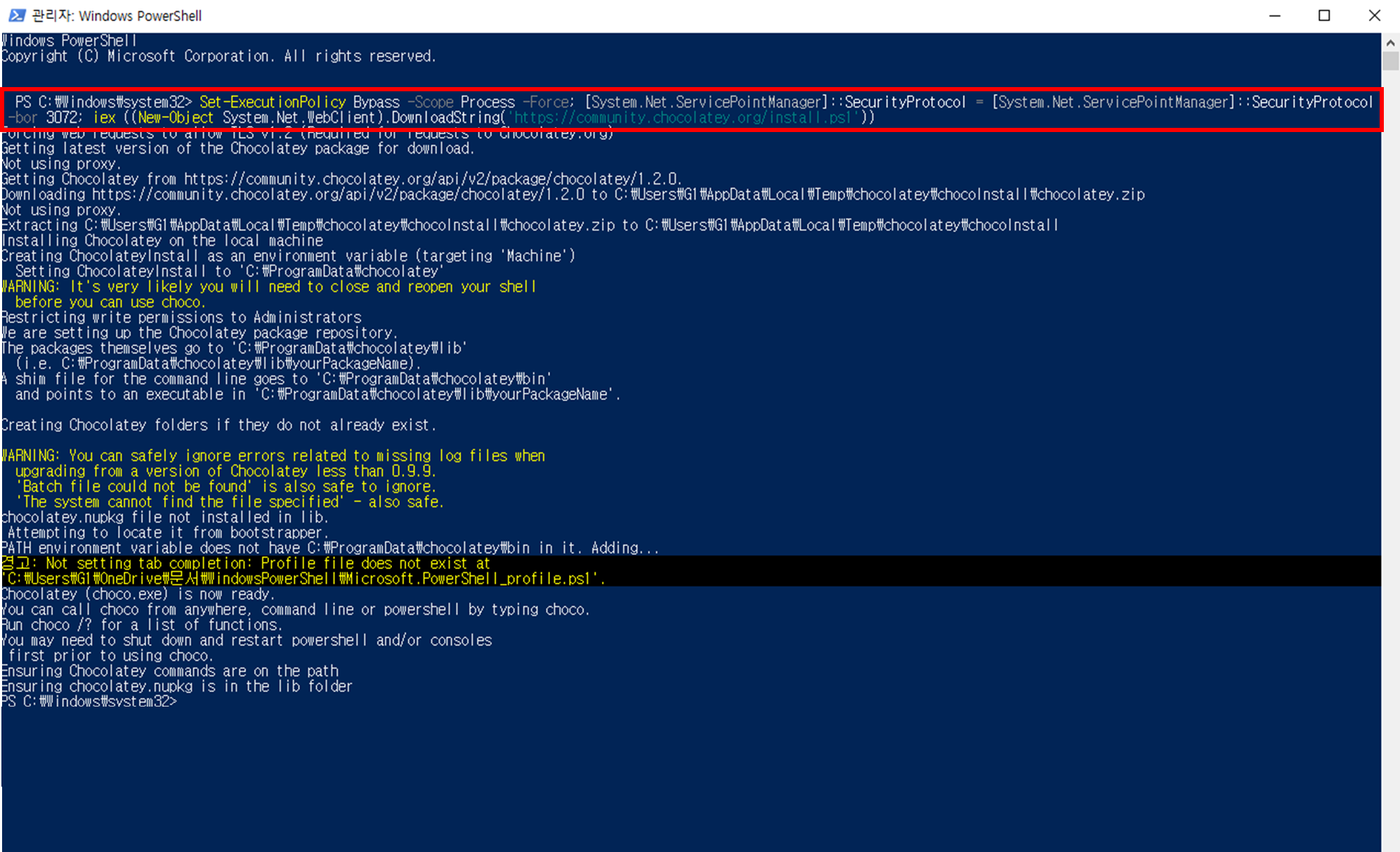
3) CHOCOLATETLY 사용하기
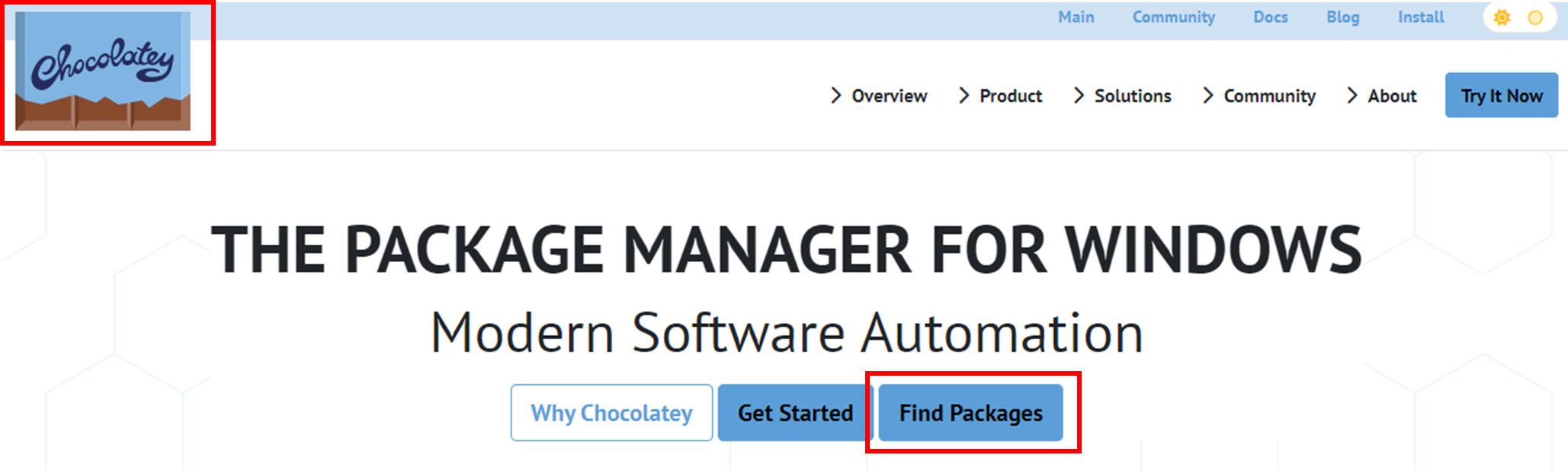
3.1) Chocolately HOME > Find Package : 필요한 Package를 찾아보자!
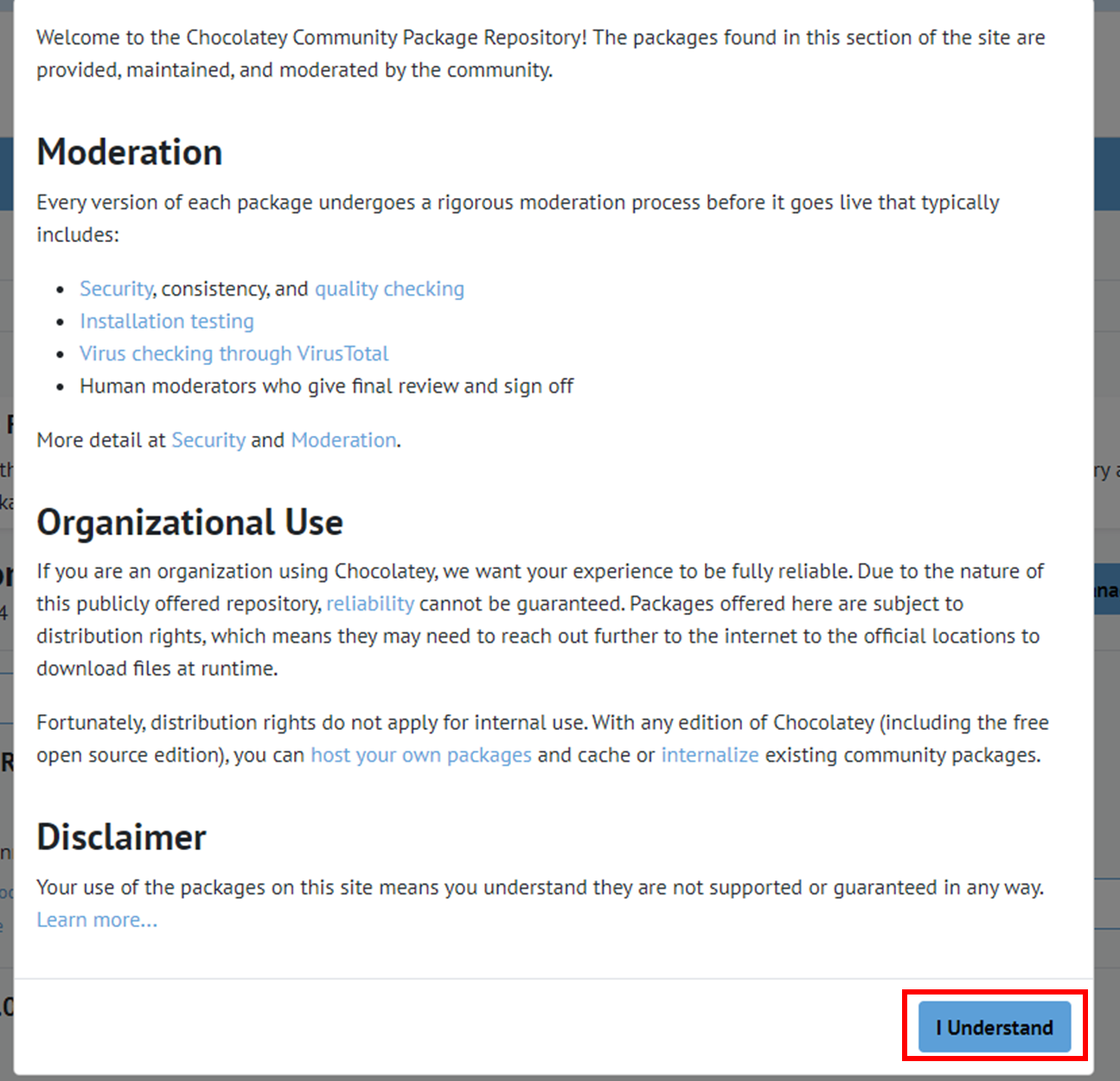
3.2) 약관 및 Disclaimer 동의 > I Understand
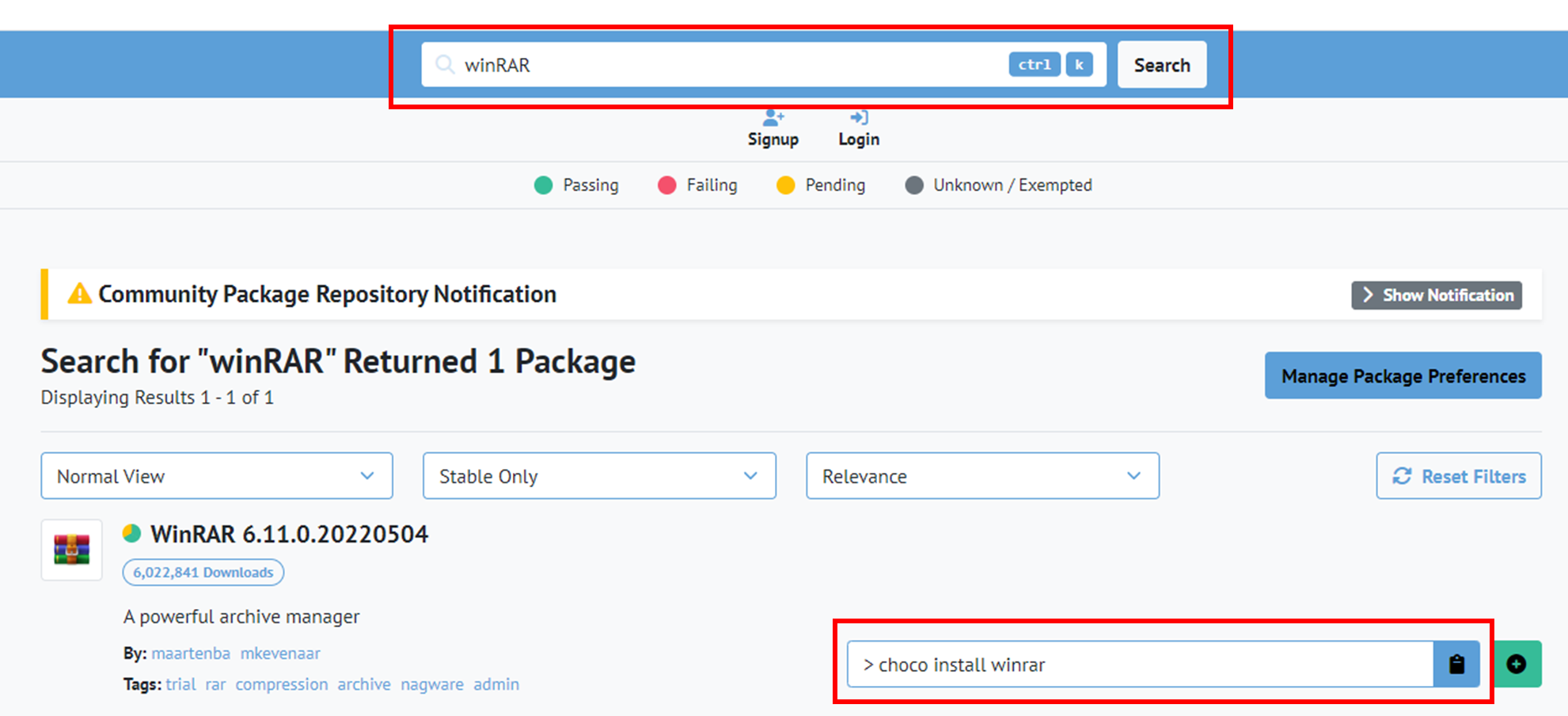
3.3) 통합 검색창에 필요한 Package 이름을 적고 > 설치할 때 쓰는 명령어 복사 후 그대로 PowerShell 창에 붙여넣으면 끝!
'IT_Engineer > Unix & Linux (Bash)' 카테고리의 다른 글
| [Linux] 서버 사용량을 체크하는 df와 du (0) | 2021.07.20 |
|---|---|
| [Linux] NET-TOOL 설치하기 (0) | 2021.06.11 |
| [Linux] 리눅스 환경 정보 확인 총정리 (0) | 2021.03.22 |
| [Linux] TAR 압축 묶기/풀기 (0) | 2021.01.18 |
| [Linux] AWK와 SED (0) | 2020.12.08 |